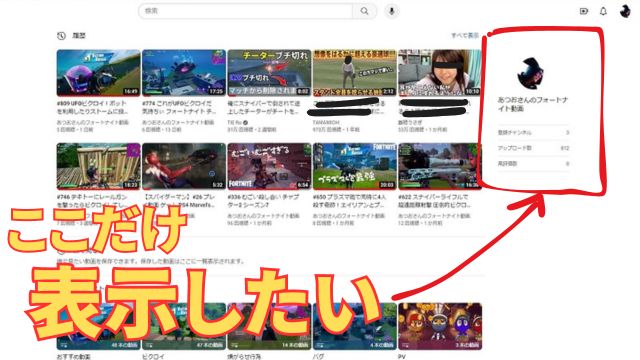
YouTubeライブラリーの履歴の欄を非表示にしてアップロード数などだけを表示させたい Google chrome の場合
atsuo3
あつおさんのブログ
VB.NETのWebView2でブラウザ内のどこがでリンクなどがクリックされたとき、リンク先のページを開かずにリンク先のURLだけを取得するJavaScriptのコードを考えました。リンク先でさらにリダイレクトされる場合は対象外です。
アプリを作る時役立つよ!
document.body.onclick = function(event) {
// クリックされた要素を取得する
var element = event.target;
// A要素の場合、hrefをWebviewに送信して処理を終了する
if (element.tagName === "A") {
window.chrome.webview.postMessage(element.href);
return false;
}
// クリックされた要素の親要素を取得する
var parent = element.parentNode;
// 親要素をすべて書き出す
while (parent !== null) {
// 親要素がAの場合、hrefをWebviewに送信してループを終了する
if (parent.tagName === "A") {
window.chrome.webview.postMessage(parent.href);
return false;
}
// 親要素の親要素を取得する
parent = parent.parentNode;
}
// 親要素が見つからない場合、空文字をWebviewに送信する
window.chrome.webview.postMessage("");
// 処理を終了する
return false;
};クリックされたHTMLの要素がAならそのままリンクを見つけて返します。クリックされた要素の中にhtmlのAが存在してる場合もありますが、普通にクリックしたときそのURLに飛ぶことは無いはずなので子要素は除外して大丈夫だと思います。しかしクリックされた要素がh3の場合もあります。
<a href="URL" class="my-class">
<h3>あいうえお</h3>
</a>こういう場合はH3で取得してしまうので親要素を探さないといけません。もし見つからないとしたらそれはリンクではありません。
まとめると、クリックされた要素がAならhrefを取得して抜ける。Aじゃなければ1つ上の親要素がAかどうか調べる。違えばさらに1つ上の親要素か調べる。Aならばhrefを取得して抜ける。見つからなければそれはリンクではないので何も返さない。です。
return false; を書かないとリンク先に飛んじゃいます。